QUIZ PERTEMUAN 5 DATA MINING

Bagian 1. Pendahuluan
Di era modern, meningkatkan kualitas pendidikan menjadi semakin sulit.
Tingkat kelulusan yang tepat waktu dan durasi studi mahasiswa di perguruan
tinggi adalah dua indikator keberhasilan pendidikan. Oleh karena itu, sangat
penting untuk memahami dengan baik komponen yang memengaruhi kelulusan tepat
waktu. Tujuan dari laporan ini adalah untuk melakukan analisis menyeluruh
tentang komponen yang mempengaruhi kelulusan tepat waktu dan lama studi di
lingkungan akademik. Di antara tugas analisis yang dilakukan adalah integrasi
dan pembersihan data serta pengenalan pola atau tren yang mempengaruhi lulusan
secara cepat. Dalam analisis lulusan tepat waktu, masalah berikut akan dibahas.
1. Langkah-langkah apa saja dalam integrasi dan
pembersihan data serta analisis pola lulusan tepat waktu?
2. Bagaimana hasil analisis statistik tersebut?
Data yang digunakan yaitu data transkip_nilai
dan data lulusan dari universitas. Data transkrip nilai sebanyak 256299
mencakup detail nilai yang diperoleh mahamahasiswa untuk mata kuliah yang
diambil. Data transkip memiliki tipe data berikut.
|
Variabel |
Tipe
Data |
|
id |
int64 |
|
nim |
object |
|
kode_mk |
object |
|
nama_mk |
object |
|
nama_mk_indo |
object |
|
nama_mk_ing |
object |
|
nilai_grade |
float64 |
|
nilai_total |
float64 |
|
semester |
int64 |
|
sks_mk |
int64 |
|
grade |
object |
Sedangkan data lulusan sebanyak 4542 data
memberikan informasi demografis dan akademik mahamahasiswa, termasuk tanggal
masuk dan lulus, serta predikat kelulusan. Data lulusan memiliki tipe data
sebagai berikut.
|
Variabel |
Tipe
Data |
|
nim |
object |
|
prodi |
object |
|
predikat |
object |
|
tanggal_lulus |
object |
|
tgl_masuk |
object |
|
status_masuk |
int64 |
|
jenis_kelamin |
int64 |
|
tahun_lahir |
int64 |
|
status_pegawai |
int64 |
|
nim |
object |
|
prodi |
object |
Bagian
2. Pembahasan
2.1 Integrasi
dan Pembersihan data
Pertama, data transkip nilai dan lulusan dikumpulkan untuk digunakan. Parameter df_transkip digunakan untuk data transkip nilai dan df_lulusan untuk data lulusan. Gambar berikut menunjukkan lima data awal dari masing-masing dataset.


Kemudian,
melakukan proses integrasi dan pembersihan data sebagai berikut :
2.1.1
Mencari Indeks Prestasi Semester (IPS) setiap semester permahamahasiswa IPS
merupakan hasil pencapaian di tiap semester dalam bentuk indeks prestasi. IPS
dihitung dengan cara sebagai berikut.
1. Mencari nilai
kamulatif per mata kuliah pada satu semester.
nilai
kamulatif = nilai grade (besaran nilai) × SKS
2. Setelah mendapatkan
nilai kamulatif per mata kuliah, selanjutnya menjumlahkan semua nilai kamulatif
selama satu semester.
3. Selanjutnya hasil penjumlahan tersebut dibagi dengan total SKS yang diajukan selama satu semester.
IPS
=
Adapun codingan untuk menghitung IPS
adalah sebagai berikut:
Pada ilustrasi kode di atas adalah membuat variabel ‘ips_df’. Kemudian pada variabel tersebut dilakukan penggabungan data transkip pada kolom ‘nim’ dan ‘semester’. Selanjutnya dilakukan perhitungan pada kolom ‘nilai_grade’ dikalikan dengan ‘sks_mk’ dan menjumlahkan hasilnya. Kemudian membagi hasil penjumlahan tersebut dengan total ‘sks_mk’ per semester. Selanjutnya hasil IPS tersebut dibulatkan menggunakan fungsi ‘round()’ menjadi dua angka di belakang koma, dan disimpan pada parameter ‘IPS’. Sehingga hasil yang didapatkan adalah sebagai berikut.

2.1.2
Menggabungkan IPS dengan data lulusan
Langkah selanjutnya adalah
menggabungkan hasil perhitungan IPS pada ‘ips_df’ dengan data lulusan pada
‘df_lulusan’ dengan fungsi merge berdasarkan kolom ‘nim’. Penggabungan tersebut
dilakukan di dalam variabel ‘merged_df’.

Dari
Pengabungan tersebut menghasilkan 36227 baris dan 11 kolom.

2.1.3
Mencari durasi studi mahasiswa
Untuk menghitung durasi studi
mahamahasiswa dilakukan dengan mengurangkan ‘tanggal_lulus’ dan ‘tgl_masuk’.
Namun sebelumnya telah dijelaskan bahwa ‘tanggal_lulus’ dan ‘tgl_masuk’
menggunakan tipe data object, sehingga perlu diubah menjadi datetime. Mengubah
tipe data menggunakan fungsi datetime().

Selanjutnya menghitung durasi studi setiap mahamahasiswa dengan mengurangi ‘tanggal_masuk’ dari ‘tgl_lulus’, kemudian dibagi dengan 365 hari (satu tahun). Hasilnya dibulatkan ke satu desimal untuk mendapatkan durasi studi dalam tahun.

Kemudian mengabungkan hasil durasi studi
ke dalam satu kolom dengan menggunakan format ‘tahun, bulan, dengan data durasi
‘merge_data’ dengan fungsi merge berdasarkan kolom ‘durasi_studi’. Yang kemudian menambahkan kolom ‘lulus tepa
waktu’ berdasarkan hasil kondisi durasi studi.

Hasilnya adalah sebagai berikut

2.1.4
Pembersihan data, mengidentifikasi, dan mengilangkan mahasiswa pindahan
Pembersihan data yang dilakukan meliputi pengecekan missing value dan duplikasi. Missing value menggunakan fungsi ‘isnull()’ dan ‘sum()’ untuk menjumlahkan nilai yang hilang atau kosong jika ada.

Kode tersebut menghasilkan nol (0) missing value pada setiap kolom sehingga tidak perlu penghapusan missing value. Hasilnya dapat dilihat pada gambar di bawah ini.

Selanjutnya menghapus mahamahasiswa
pindahan. Pada data ini mahamahasiswa pindahan atau tidak terdapat pada kolom
‘status_masuk’ yang terdiri dari nilai ‘0’ dan ‘1’. Pada mahamahasiswa pindahan
ditandai dengan nilai ‘1’. Sehingga pada langkah kali ini, akan menghapus kolom
‘status_masuk’ yang bernilai ‘1’ dengan menggunkan fungsi drop().
Untuk
mengecek apakah proses penghapusan tersebut berhasil atau tidak bisa dilakukan
cetak jumlah data menggunakan ‘print’

2.1.5
Standarisasi format tanggal dan jenis kelamin
Karena format tanggal sudah diganti menjadi tipe data datetime sehingga tidak perlu dilakukan standarisasi. Selanjutnya adalah standarisasi jenis kelamin. Pada data saat ini jenis kelamin terdiri dari nilai ‘0’ dan ‘1’. Standarisasi yang akan dilakukan yaitu mengganti nilai ‘0’ menjadi ‘laki-laki’ dan ‘1’ menjadi ‘perempuan’.
Sehingga data terbarunya menjadi sebagai berikut:

2.2
Mencari tren atau pola yang
mempengaruhi lulusan tepat waktu
2.2.1
Mengidentifikasi hubungan antara IPS
dengan lulusan tepat waktu.
Pada
langkah ini dilakukan untuk memahami apakah terdapat perbedaan signifikan dalam
rata-rata nilai IPS antara mahamahasiswa yang lulus tepat waktu dan yang tidak
tepat waktu. Untuk itu perlu memastikan kolom ‘lulus tepat waktu’ memiliki data
numerik dan apakah ‘ips’ dan ‘lulus tepat waktu’ memiliki korelasi

Pada kasus ini pengujian statistik menggunakan ‘ttest_ind’ dari pustaka ‘scipy.stats’ yang dapat dilihat pada gambar berikut.

Berdasarkan
gambar kode di atas, langkah pertama memilih kolom yang diperlukan yaitu ‘IPS’
dan ‘lulus_tepat_waktu’. Selanjutnya menghitung rata-rata nilai ‘IPS’ untuk
kelompok lulus tepat waktu dan tidak tepat waktu pada kolom ‘lulus_tepat_waktu’.
Berikutnya dilakuakn uji statistik untuk menentukan apakah terdapat perbedaan
yang signifikan antara rata-rata IPS antara kedua kelompok.

Dari
hasil di atas terdapat perbedaan yang signifikan dalam rata-rata IPS antara
kelompok lulus tepat waktu dan tidak tepat waktu.
2.2.2 Analisis Kolerasi Positif antara predikat kelulusan ‘Pujian’ dengan lulusan tepat waktu

Pada gambar di atas, pertama-tama dilakukan analisis frekuensi predikat berdasarkan lulus tepat waktu menggunakan filtered_data. Data frekuensi tersebut disimpan dalam variabel ‘predikat’. Kemudian dilakukanpenghitungan frekuensi predikat, yang kemudian menghasilkan data seperti gambar dibawah ini.

2.2.2 Analisis durasi studi lebih pendek berkorelasi dengan predikat kelulusan yang lebih baik

Pertama menghitung total jumlah dari lulusan terlebih dahulu, sehingga data predikat kelulusan valid yang dipertimbangkan. Selanjutnya, hitung jumlah lulusan dan proposi keseluruan lulusan tepat waktu. Sehingga akan menghasilkan seperti gambar dibawah ini.

Hasilnya
menunjukkan bahwa rata-rata durasi studi lebih rendah yang mendapat predikat
kelulusan yang lebih tinggi, yaitu 'Pujian' dan 'Sangat Memuaskan',
dibandingkan dengan siswa yang mendapat predikat 'Memuaskan'. Visualisasi
durasi studi berdasarkan predikat dapat dilihat pada gambar berikut.

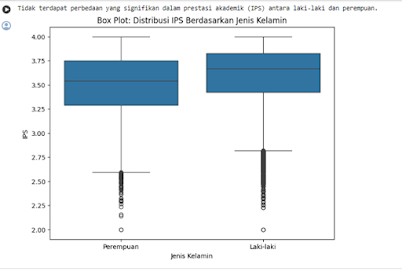
2.2.3
Analisis rata-rata nilai total apakah ada
perbedaan signifikan dalam prestasi akademik berdasarkan jenis kelamin
pertama
tama pisahkan data menjadi dua kelompok jenis kelamin, menggunakan 'merge data'
dengan kolom 'jenis_kelamin'. yang kemudian pengujian t-student menggunakan
't-stastistic.

Sehingga hasilnya adalah sebagai berikut



Komentar
Posting Komentar